우리에게 보여지는 네이버 블로그 URL은 사실 가짜 주소인 것을 알고 계신가요? 이번 포스팅에서는 네이버 블로그의 도서 리뷰를 크롤링하는 과정에서 학습한 내용을 공유합니다.
네이버 추천도서 정보 웹 크롤링
추천모델을 생성하는 연습용 프로젝트를 진행하고 있습니다. 네이버 책의 소설 > 나라별 소설 카테고리의 추천도서 969권의 정보를 수집, Word2Vec 모델 기반으로 추천 모델을 생성하고자 합니다.
수집하고자 하는 책 정보의 항목은 다음과 같습니다.
- 책 제목 텍스트
- 책 상세 웹페이지 URL 텍스트
- 상세 웹페이지의 ‘책소개’ 항목 텍스트
- 상세 웹페이지의 ‘책 속으로’ 항목 텍스트
- 상세 웹페이지의 ‘네티즌 리뷰’ 항목 텍스트
- 개인들의 네이버 블로그에 작성된 책 리뷰
- 리뷰 총합이 100건을 초과할 경우 100건만 수집
문제는 리뷰 텍스트의 수집에서 발생했습니다. Selenium(chromedriver)와 BeatifulSoup 등 다양한 방법으로 접근해 봐도, 본문 텍스트를 가져오지 못했는데요.
네이버 API를 사용하여 urllib.request.Request 객체에 API 사용자 인증 정보를 header 추가하여도 마찬가지였습니다. 무엇이 문제였을까요?
가짜 URL, 진짜 URL
네이버 블로그에 업로드된 포스트는 각각 가짜 주소와 진짜 주소를 가지고 있습니다. 가짜 주소는 우리가 일반적으로 네이버 블로그 포스트에 접근할 때 보여지는 주소이며, 웹 크롤링이 불가능하도록 본문 등 콘텐츠 텍스트가 숨겨져 있습니다.
도저히 콘텐츠 텍스트를 얻을 수가 없었던 이유입니다. 가짜 URL에서 정보를 가져오려고 시도했던 것이니까요. 이와 반대로, 진짜 URL은 크롤링이 가능한 주소이며, 숨겨져 있습니다.
어디에 숨겨져 있을까요? 아래 도서 리뷰 포스트를 예시로 들어보겠습니다.
- https://blog.naver.com/box1042/220907410772
크롬 브라우저로 위 주소에 접속하여 마우스 우클릭 > 검사(investigation)를 찍어 보면 해당 페이지의 코드를 확인할 수 있습니다. Ctrl+F로 ‘mainFrame’을 검색하면 다음과 같은 결과를 확인할 수 있는데요.
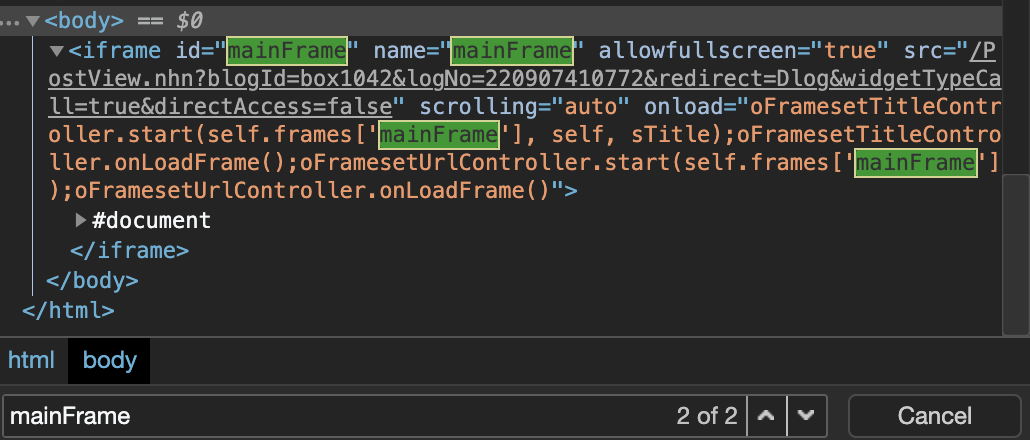
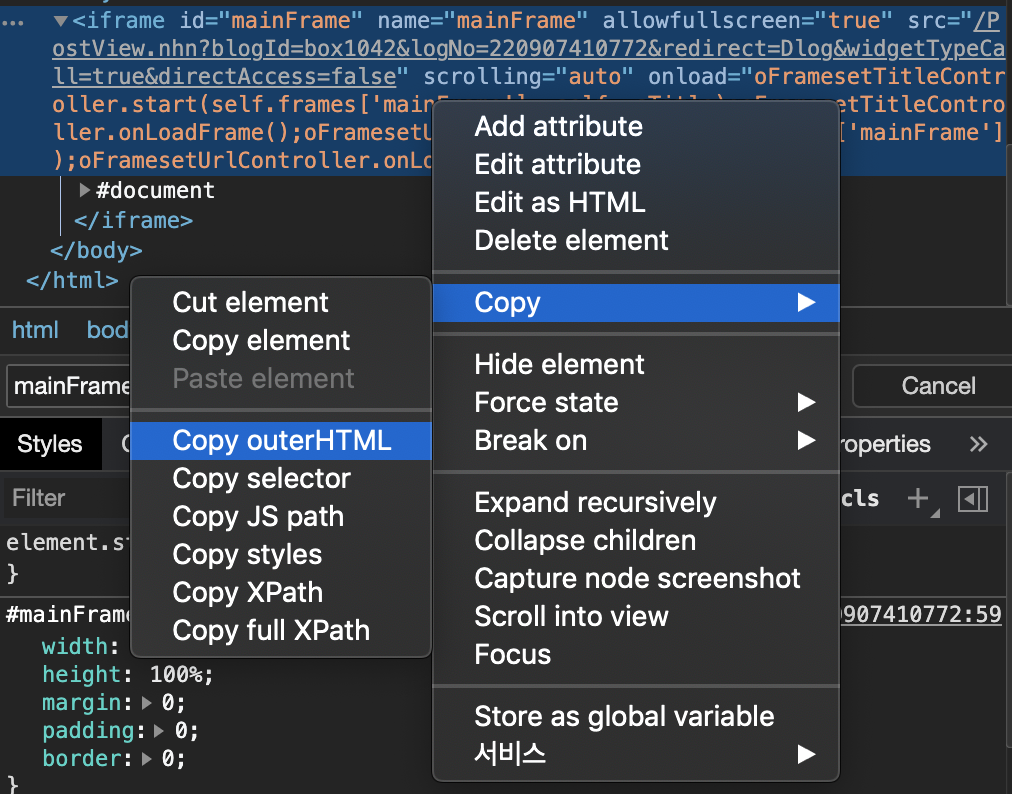
위 코드를 마우스 우클릭하여 Copy > Copy outerHTML하면, id와 name 속성을 mainFrame으로 가지는 iframe에 대한 코드를 확인할 수 있습니다.
1 | |
위 코드에서 src라는 속성에 부여된 텍스트가 있습니다. “/PostView.nhn?blogId=…“로 시작하는 텍스트인데요. 이 텍스트가 바로 진짜 주소값의 일부를 가리킵니다. 정확히 말하면, https://blog.naver.com 다음에 오는 주소값입니다.
정리하면, https://blog.naver.com/box1042/220907410772 라는 네이버 블로그 포스트의 웹크롤링 가능한 진짜 주소는 다음과 같게 됩니다.
1 | |
이제 가짜 주소로부터 진짜 주소를 획득하는 방법을 알았습니다. 아래와 같은 코드를 작성하여, 네이버 블로그 포스트의 본문 내용을 가져와 봅니다.
1 | |
위 코드의 동작을 확인합니다.

진짜 URL 속에 숨겨진 “진짜 진짜 URL”
정상적인 작동을 확인했지만, 작동하지 않는 경우도 발생했습니다. 예를 들면 다음과 같은 블로그 포스트였는데요.
- https://blog.naver.com/here-now-lee/222215012401
동일한 방식으로 위에서 작성한 함수를 실행했지만 None이 반환되었습니다. 위 블로그 포스트의 진짜 URL을 찾아서, 웹브라우저를 통해 직접 접근을 시도해 보았습니다. 그 결과, 다음과 같은 팝업을 확인했습니다.

위에서 작성한 get_naver_blog_text() 함수 내부에 아래 print 문을 삽입하여, 진짜 URL 주소의 div#postViewArea 태그에 무엇이 담겨 있는지 확인해 보고자 합니다.
크롤링에 문제가 발생한 블로그 포스트의 제목은 “
1 | |

그렇다면, 진짜 URL로 받아 온 BeautifulSoup 객체에는 무엇이 담겨 있을까요? 마찬가지로 print문을 호출하여 HTML 코드가 잘 담겨 있는지 확인해 봅니다.
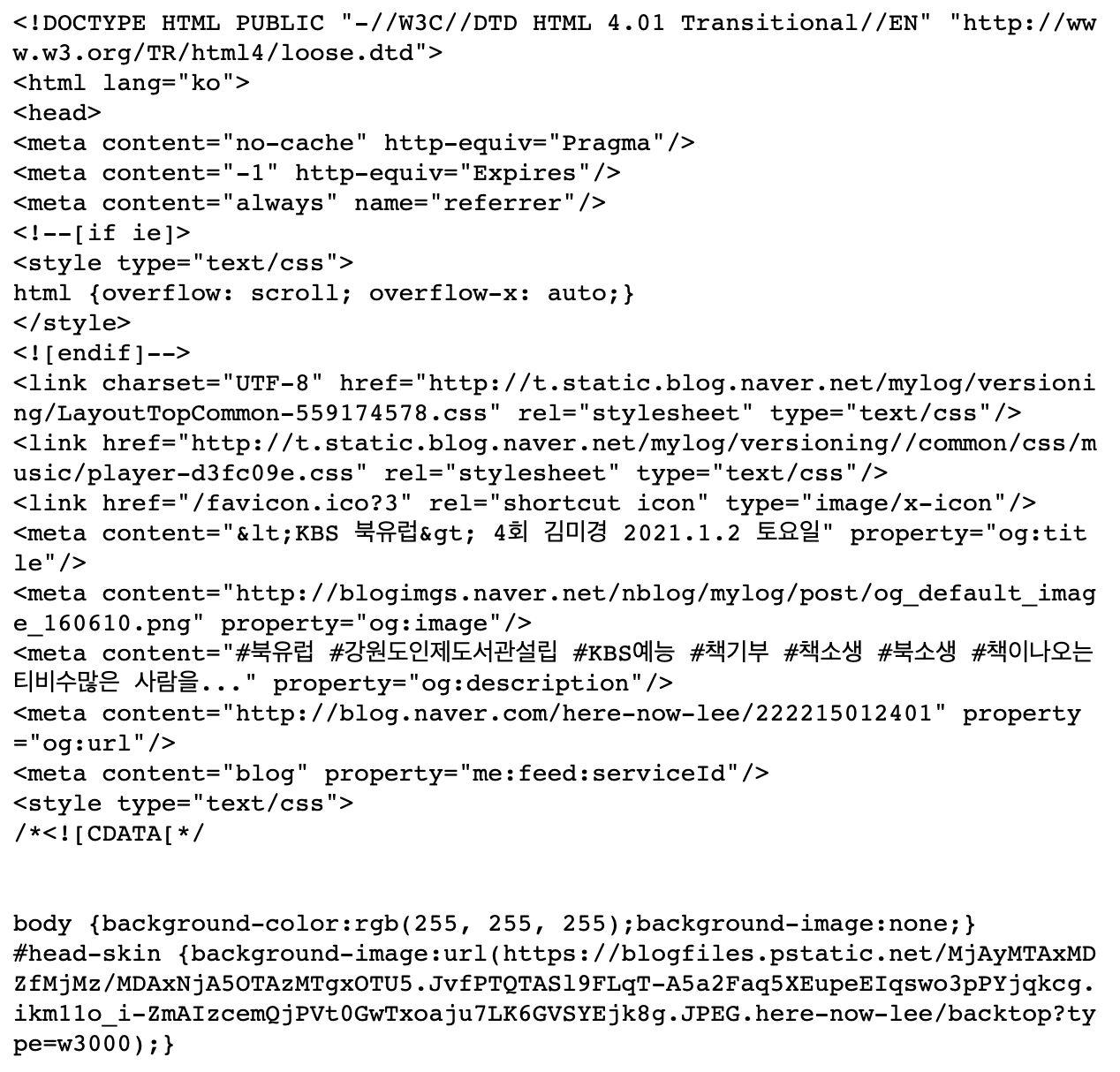
get_naver_blog_text() 함수는 진짜 URL로 접근할 수 있었고, 정상적으로 BeautifulSoup 객체를 생성했습니다. 그렇다면, get_naver_blog_text() 에서 가져오고자 시도하는 #div#postViewArea 태그가 존재하지 않을 가능성이 있습니다.
크롬브라우저로 문제가 발생한 포스트로 접속해, 검사 윈도우를 열어 postViewArea를 검색해 봅니다.
위 블로그에 접속하여
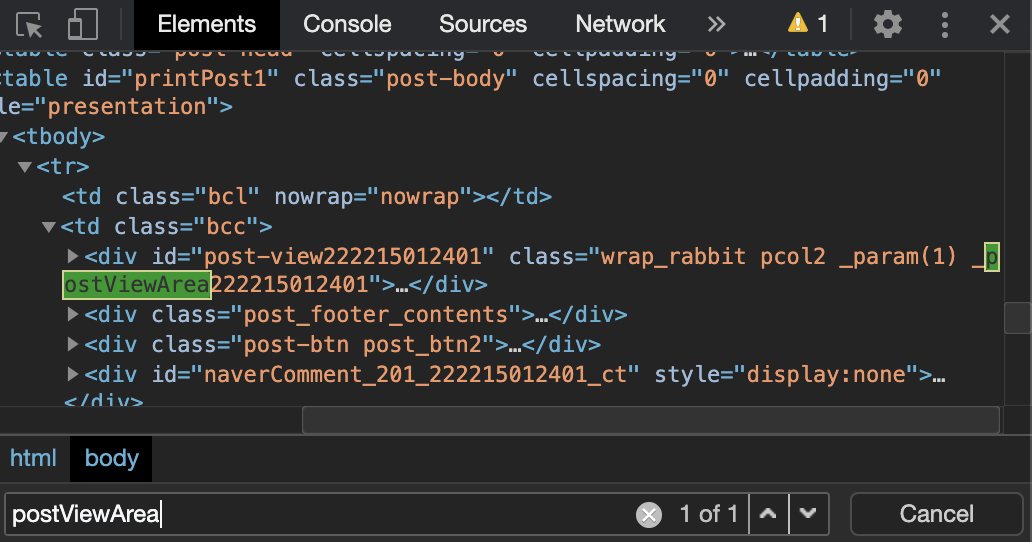
div#postViewArea 비슷해 보이기는 한데, 뒤에 길다란 숫자가 붙어 있습니다. 이것 외에 정확히 div#postViewArea 와 일치하는 요소를 찾을 수는 없었습니다. 그런데 저 숫자가 왠지 낯이 익습니다.
해당 포스트의 진짜 URL 주소값 중 logNo=222215012401 이라는 부분이 존재합니다. 크롬브라우저 검사로 확인한 숫자값과 일치하는 것을 확인할 수 있습니다.
div#postViewArea 대신 일종의 고유번호인 logNo를 사용한 변칙 태그가 존재한다고 생각해볼 수 있겠습니다. 그렇다면, 앞서 작성한 get_naver_blog_text() 함수가 불러오지 못한 텍스트는 변칙 태그가 적용된 블로그일 가능성이 높겠습니다.
그렇다면 진짜 URL로부터 logNo를 파싱한 뒤, f'div#post-view{logNo}' 형식의 태그에 대하여 다시 BeautifulSoup를 생성하도록 함수를 보완하여 작성합니다.
테스트 과정에서, 이러한 접근 방법은 네이버 API가 필요하지 않음을 알게 되어 해당 부분은 삭제했습니다. 또한 블로그 포스트의 제목(키워드)이 아닌 블로그 포스트의 url(가짜 주소)를 인자로 받아옵니다.
1 | |
이 함수를 가지고, 기존 get_naver_blog_text() 로 텍스트 가져오기에 실패했던 아래 링크를 새로 작성한 get_naver_blog_text_v2() 함수의 인자로 넣어 봅니다. 성공적으로 본문 텍스트를 가져오는 것을 확인했습니다.

그래도 끝이 아니라고?
서두에 밝혔듯이 본 크롤링의 목적은 콘텐츠 추천을 위한 사용자 리뷰 텍스트 수집이었습니다. 따라서, 사전에 따로 수집해 둔 블로그 url들에 대하여 get_naver_blog_text_v2() 함수를 적용, 본문 텍스트로 변환해 보겠습니다.
1 | |
설마 에러가 나겠어 하면서 최종 예외처리 사항으로 url과 real url을 출력하도록 코드를 작성해 두었었는데요. 그 설마가 발생했습니다.
에러가 발생한 주소는 대략 이렇습니다.
- https://book.naver.com/bookdb/review_view.nhn?bid=2618306&review.seq=1401616
접속해 보면, 네이버 블로그에 작성된 글을 네이버 책 페이지 내부에 가져온 형태입니다. 대략 2000년대 후반에 작성된 글들입니다. 이것이 마지막 예외이길 기원하며, get_naver_blog_text_v2() 함수의 최종 예외처리 구간에 아래 코드를 추가합니다.
1 | |
반복되는 코드들을 inner function으로 정리해주고, get_naver_blog_text_v3 함수에 문제가 발생한 리뷰 페이지 링크를 넣어 테스트해 봅니다.

기능이 어느 정도 만들어졌으므로, 간단한 코드 최적화를 수행합니다. 사용되지 않는 코드를 삭제하고, 불필요하게 함수 실행 시간을 지연시키는 부분을 개선합니다.
- 사용되지 않는
re.compile코드 삭제 > 이후 전처리 과정에서 사용 - 불필요한
time.sleep코드 삭제- 함수 실행 과정에서 최초 인자로 입력받는 url 텍스트가
create_soup_from_url함수로 전달되지 않는 문제 발생 - 함수가 빠른 속도로 반복 실행되면서 url 인자를 받아오지 못한다고 생각하여
time.sleep코드를 삽입 - 문제는 url 인자 누락이 아니라, url 값 자체가 nan이었기 때문에 발생한 문제
time.sleep코드를 삭제하고 최초 입력받는 url 값이 nan인지 검사하고, nan이면 None 리턴하는 코드 삽입
- 함수 실행 과정에서 최초 인자로 입력받는 url 텍스트가
- 비공개 처리 또는 삭제된 리뷰 등 최종 예외처리 되었을 경우 None 반환하는 코드 추가
1 | |
네이버는 서비스 기간이 오래된 대형 포털 서비스인 만큼, 본문에서 다루었던 유형 이외에도 다양한 예외들이 존재할 것입니다. 단 하나도 놓치지 않는 완벽주의적 자세는 분명 박수받아 마땅할 것이지만, 언제나 시간과 리소스는 한정되어 있음을 간과해서는 안 되겠죠. 마지막 코드 최적화 작업을 통해, 1000건의 리뷰 텍스트를 불러오는 데 걸리는 시간을 20분 이상에서 3분 미만으로 단축할 수 있었습니다.
조금이나마 도움이 되셨으면 좋겠습니다. 이상으로 오늘의 포스팅을 마칩니다.