에러 분석을 진행하는 동안, 당신은 디벨롭먼트 셋 데이터 일부가 오분류된 것을 알게 될 수도 있습니다. 여기서 “오분류“라는 말은, 데이터가 알고리즘에 투입되기도 전에 휴먼 에러로 인해 라벨링이 잘못 되었음을 의미합니다.
Cleaning up mislabeled dev and test set examples
이는 (x, y)라는 데이터에서 클래스 라벨 y가 잘못 지정되었음을 뜻하는데요. 예를 들어, 고양이가 없는 어떤 사진들이 고양이로 라벨링이 되었거나, 그 반대일 경우를 말합니다. 이렇게 사전에 잘못 분류된 데이터가 상당히 많다고 의심될 경우, 이러한 오분류 데이터의 비율을 추적하는 카테고리인 Mislabeled를 스프레드시트에 추가하세요:
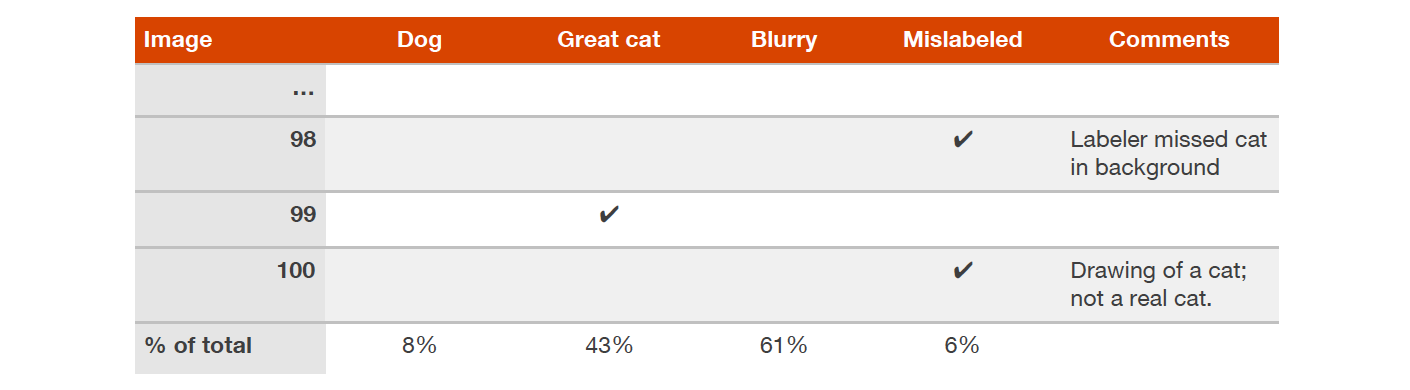
디벨롭먼트 셋에 정의된 라벨들을 수정해야만 할까요? 디벨롭먼트 셋의 목표는 알고리즘의 성능을 빠르게 평가해서 어떤 알고리즘이 나은지 결정하기 위한 것임을 기억하세요. 만약 사전 오분류된 데이터 비중이 알고리즘 성능 판단을 저해한다면, 잘못 정의된 디벨롭먼트 셋 라벨들을 수정해야 합니다.
예를 들어, 당신의 분류기 성능이 다음과 같다고 해 봅시다:
- 디벨롭먼트 셋에 대한 전반적인 정확도(accuracy)
- 90% (10% overall error)
- 사전 오분류 데이터로 인한 에러
- 0.6% (6% of dev set errors)
- 기타 원인으로 인한 에러
- 9.4% (94% of dev set errors)
사전 오분류로 발생하는 0.6%의 부정확성은 당신이 개선가능한 기타 원인들로 인해 발생하는 9.4%에 비하여 중요도가 낮습니다. 물론 사전 오분류된 디벨롭먼트 셋 데이터를 하나하나 고친다고 나쁠 것은 없지만, 상대적으로 중요한 일이 아니라는 의미입니다. 머신러닝 시스템 에러가 10%이든 9.4%이든 별반 차이가 없으니까요.
당신이 고양이 분류기 성능을 계속 향상시켜서 다음과 같은 정확도를 갖게 되었다고 가정해 봅시다:
- 디벨롭먼트 셋에 대한 전반적인 정확도(accuracy)
- 98% (2.0% overall error)
- 사전 오분류 데이터로 인한 에러
- 0.6% (30% of dev set errors)
- 기타 원인으로 인한 에러
- 1.4% (70% of dev set errors)
위와 같은 상황에서 에러의 3할이 사전 오분류된 데이터로 인해 발생하고 있습니다. 이는 모델의 정확도 성능에 유의미한 영향이라고 생각할 수 있습니다. 이제 디벨롭먼트 셋의 라벨링 퀄리티를 개선하는 의미가 있다고 볼 수 있죠. 사전 오분류된 데이터를 개선함으로써 분류기 오차 발생율은 1.4% 또는 2%에 가까워질 것이고, 이는 꽤 유의미한 차이입니다.
일반적으로, 디벨롭먼트/테스트 데이터 일부가 사전 오분류된 문제는 처음부터 대응하는 문제가 아닙니다. 시스템 성능이 충분히 개선된 다음, 사전 오분류된 데이터로 인한 에러 비중이 상대적으로 커지고 나서야 대응하게 됩니다.
지난 챕터에서 우리는 강아지, 커다란 고양이과 동물, 흐릿한 사진 등의 에러 카테고리를 설정하고 개선하는 방법을 알아보았습니다. 이번 챕터를 통해, 이제 우리는 사전 오분류 카테고리를 통해서 데이터 라벨 관련 문제를 개선하는 방법도 배웠습니다.
디벨롭먼트 셋 라벨 수정과 관련된 작업을 진행하게 된다면, 디벨롭먼트 셋과 테스트 셋이 동일한 분포를 유지할 수 있도록 테스트 셋에 대해서도 동일하게 작업해 주어야 함을 반드시 기억하세요. 디벨롭먼트 셋과 테스트 셋을 동일하게 처리함으로써, Your dev and test sets should come from the same distribution에서 살펴보았던 문제를 방지할 수 있습니다. 디벨롭먼트 셋을 기준으로 모델을 열심히 향상시키고 나서 보니, 테스트 셋과 디벨롭먼트 셋이 다른 분포를 가지고 있다는 걸 깨닫는다는 아주 나쁜 시나리오 말이죠.
만약 당신이 사전 오분류된 라벨 문제를 해결하고자 한다면, 알고리즘이 올바르게 분류한 라벨과 함께 알고리즘이 틀리게 분류한 데이터 라벨도 함께 더블체크할 것을 권장합니다. 실제 라벨과 학습 알고리즘 예측값 모두 틀렸을 가능성이 있기 때문입니다. 만약 알고리즘이 잘못 분류한 데이터의 라벨만 수정할 경우, 모델 성능 추정에 있어서 편향성이 더해지는 결과가 됩니다.
만약 당신이 1000개의 디벨롭먼트 셋 데이터가 있고, 분류기 성능이 98.0%의 정확도를 갖고 있다면, 올바르게 분류된 980개 데이터 전부를 검사하는 것보다는 잘못 분류된 20개의 데이터만 검사하는 것이 더 쉬울 겁니다. 현업에서 잘못 분류된 데이터만 검사하고 지나치는 일이 빈번하게 일어나기 때문에, 디벨롭먼트 셋 일부에 편향이 발생할 수 있습니다.
이러한 편향성은 당신이 어플리케이션 제품을 개발하는 것에만 관심이 있다면 용인할 수 있지만, 연구 논문을 쓴다거나 테스트 셋 정확도를 완벽하게 비편향적으로 측정해야 한다면 문제가 될 겁니다.
deeplearning.ai를 이끄는 Andrew Ng의 책, MACHINE LEARNING YEARNING은 머신러닝 프로젝트 수행에 있어 반드시 알아야 할 개념과 노하우를 담고 있습니다. 총 58편으로 이루어진 이 책을 1편씩 번역하여 게재합니다.