딥러닝(심층 신경망)이라는 아이디어 대부분은 수십년 전부터 존재헸습니다. 왜 최근이 되어서야 대세가 되었을까요?
Scale drives machine learning progress
딥러닝 급부상의 두 가지 주요 동력은 다음과 같았습니다:
- Data availability. 사람들은 오늘날 디지털 디바이스를 더 오랜 시간 이용하고 있습니다. 그들의 디지털 활동들은 우리의 학습 알고리즘의 양식이 되는 풍부한 데이터를 만들어냅니다.
- Computational scale. 대규모 데이터셋을 활용할 수 있을 정도로 큰 심층 신경망을 학습시킬 수 있게 된 것은 수 년 전이 되어서야 가능해졌습니다.
자세하게 말하자면, 당신이 더 많은 데이터를 쌓는다 하더라도, logistic regression 등의 기존 학습 알고리즘 성능은 “평탄화”되었습니다. 이말은 곧 알고리즘의 학습 곡선이 “더 상승하지 못하고 기울기가 0에 가까워짐”을 의미합니다. 따라서 당신이 데이터를 더 넣어줘도 알고리즘은 개선되지 않습니다.
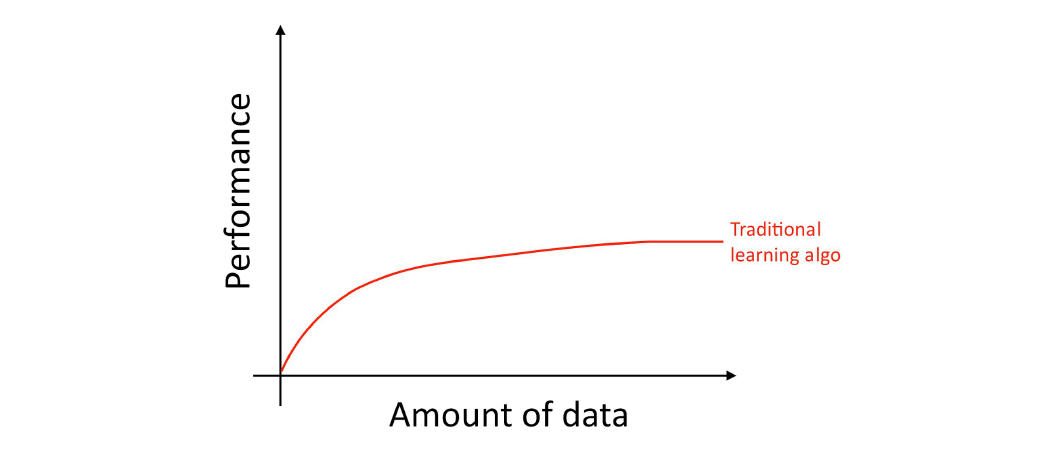
기존 알고리즘들은 우리들이 가진 방대한 데이터를 가지고 무엇을 해야 할 지 모르는 것처럼 보였습니다. 만약 당신이 작은 심층 신경망을 동일한 지도학습 태스크에 대하여 학습시킨다면, 살짝 더 나은 성능을 얻을 수 있을 겁니다:
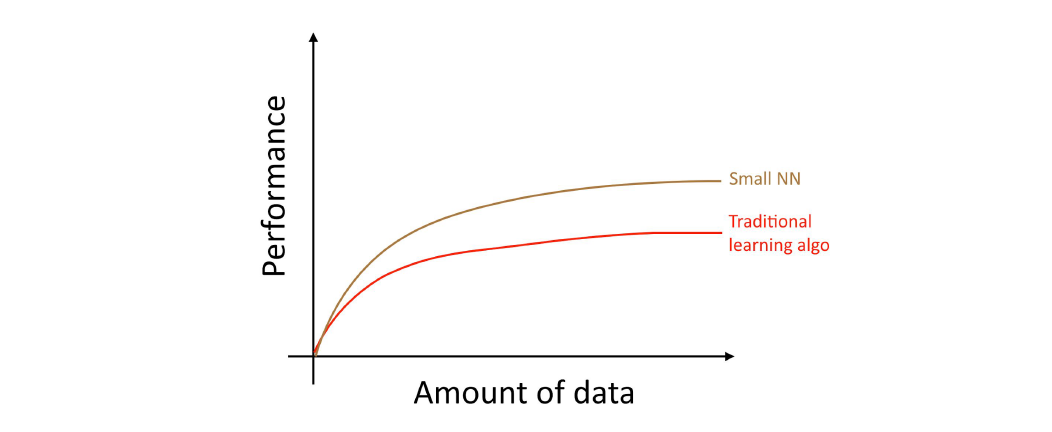
여기서 “작은 심층 신경망”이란 히든 유닛/레이어/파라미터의 숫자가 작은 심층 신경망을 의미합니다. 마침내, 당신어 심층 신경망의 크기를 늘려나감에 따라, 훨씬 좋은 성능을 얻을 수 있게 됩니다:
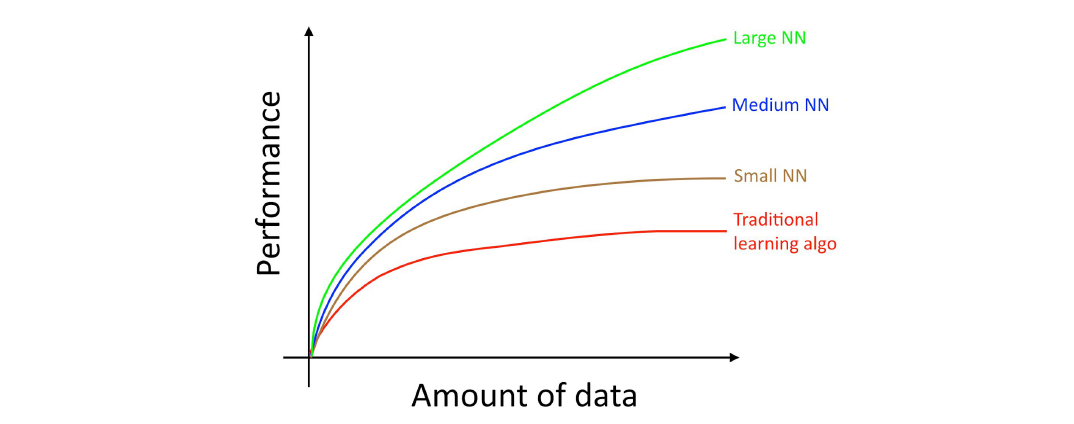
따라서, 당신은 (i) 아주 커다란 심층 신경망을 만든 다음, (ii) 대규모 데이터를 학습시킬 때 최상의 퍼포먼스를 얻을 수 있습니다.
심층 신경망의 아키텍쳐 등 다른 여러가지 디테일도 중요한 문제이며, 이러한 영역에서도 많은 혁신이 일어나고 있습니다. 그러나 오늘날 알고리즘의 성능을 개선시키는 가장 확실한 방법 중 하나는, 여전히 더 큰 네트워크에 더 많은 데이터를 학습시키는 것입니다.
(i)과 (ii)를 달성하기 위한 방법과 절차는 놀랄만큼 복잡합니다. 이 책은 (i)과 (ii)를 달성하기 위한 세부사항들을 차근차근 살펴볼 겁니다. 전통적인 학습 알고리즘들과 심층 신경망에 모두 해당되는 일반적으로 유용한 전략들로 시작해서, 딥러닝 시스템을 구축하기 위한 최신 전략들로 나아가게 될 것입니다.
===
위 다이어그램 이미지에서 모든 심층 신경망들은 작은 데이터셋에서도 전통적인 알고리즘보다 성능 우위를 보입니다. 다만 이러한 효과는 데이터셋이 큰 경우보다는 덜 일관적으로 나타날 수 있습니다. 데이터셋이 작은 경우, feature engineering 방식에 따라서 전통적인 알고리즘이 심층 신경망보다 나을 수 있습니다. 그러나 백만 건 이상의 샘플 데이터를 갖고 있다면, 나는 주저없이 심층 신경망을 택할 것입니다.
deeplearning.ai를 이끄는 Andrew Ng의 책, MACHINE LEARNING YEARNING은 머신러닝 프로젝트 수행에 있어 반드시 알아야 할 개념과 노하우를 담고 있습니다. 총 58편으로 이루어진 이 책을 1편씩 번역하여 게재합니다.