자연어처리를 활용해서 주가를 예측한다. 이야기가 들리기 시작했던 건 상당히 오래 전으로 기억합니다만, 최근 딥러닝 알고리즘의 발전에 힘입어 다시 떠오르는 주제입니다. 오늘은 벡터 차이의 의미를 동시발생 확률 비율의 차이로 파악하는 GloVe 모델과 함께, 주가 예측 목적으로 자연어 텍스트를 전처리하는 방법 등에 대해 살펴봅니다.
GloVe
GloVe Algorithm : 벡터 차이의 의미 인코딩
동시발생 확률의 비율을 통해 의미 구성 요소를 인코딩한다.
- 핵심 아이디어 = 동시 발생 확률의 “비율”이 의미 구성 요소를 encode(해석)할 수 있다
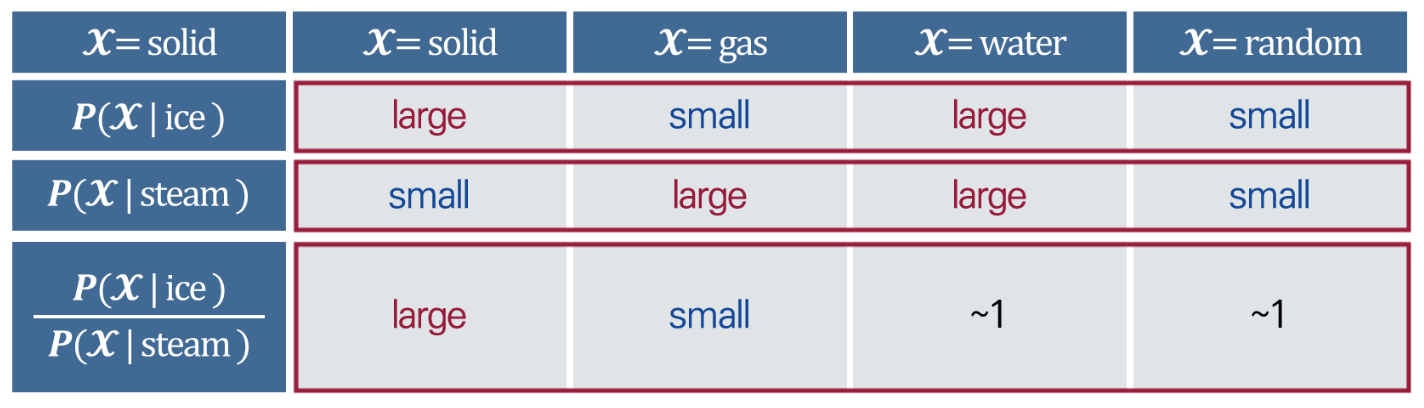
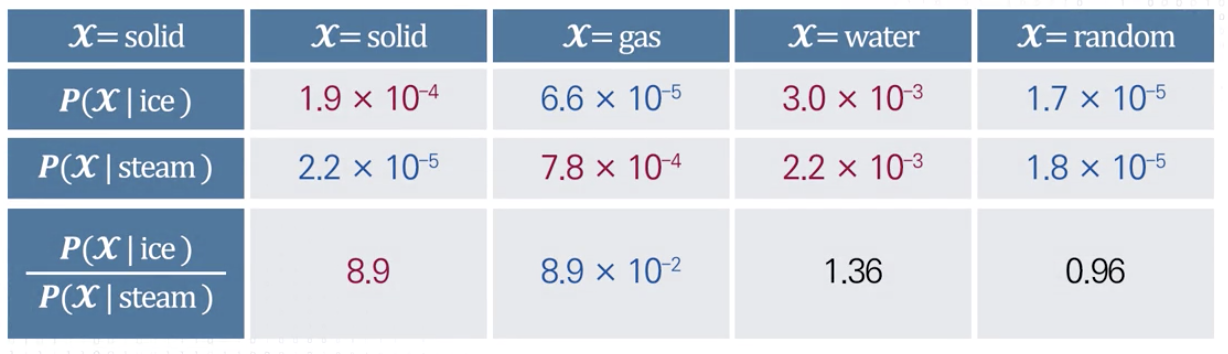
단어 벡터 공간에서 선형 의미 구성 요소로 동시 발생 확률의 비율을 사용하는 방법
Log-bilinear 모형
- 단어 벡터 공간에서 선형 의미의 구성 요소로 동시 발생 확률의 비율을 사용
Log-bilinear 모형
- 동시 발생 확률의 비율값을 활용
- 백터의 차이값을 사용하여 동시 발생 확률의 비용을 적용
- 의미의 차이 = 비율의 차이
What is GloVe?
- Global Vectors for Word Representation
- 카운트 기반 + 예측 기반 방법론 모두 사용
- “GloVe: Global Vectors for Word Representation”, Pennington et al., 2014
- 카운트 기반의 LSA(Latent Semantic Analysis)와 예측 기반의 Word2Vec 2개 접근법의 단점 보완
- 실제로는 Word2Vec과 유사한 성능을 보임
- case별 적합한 모델 선택
카운트 기반 : LSA
- 각 문서에 포함된 단어 빈도수를 카운트 한 행렬(=전체 통계 정보)로 받아 차원 축소
- 특이값분해를 통해 의미 끌어내는 방법론
- 카운트 기반, 말뭉치의 전체적인 통계 정보 고려
- 단어 의미 유추 작업에는 성능 떨어짐
예측 기반 : Word2Vec
- 실제값과 예측값에 대한 오차를 손실 함수를 통해 줄여가면서 학습
- 단어 간 유추 작업에는 LSA보다 뛰어난 성능
- 중심단어 - 주변단어 간 일반화된 의미 추론 규칙을 학습
- 임베딩 벡터가 윈도우 크기 내에서만 주변 단어를 고려
- 말뭉치의 전체적인 통계 정보를 반영하지 못함
NLP와 주가
전처리 과정 (Preprocess)
- 특성을 추출하기까지 작업의 양이 방대함
- 자연어처리는 특별히 전처리 과정이 힘든 과정
- 감성분석 > 비꼬는 말의 최신 언어, 은어 등
- 기계가 파악하기 어려움
- 사전처리의 정확도에 따라 예측력이 엄청나게 향상될 수 있음
특성추출 (Feature Extraction)
| 이름 | 설명 |
|---|---|
| 트윗 | ”@” 기호 > “PERSON” “#” 기호 > “TOPIC” |
| 정제 | 말뭉치의 노이즈 데이터 제거 |
| 정규화 | 표현 방법이 다양한 단어들을 하나의 단어로 통합 |
| 슬랭 | 속어를 정규화된 단어로 대체 |
| 불용어 | 더 이상 사용되지 않으므로 제거 |
| Negation | 부정표현을 Negation이라는 토큰으로 대체 |
| 품사 태거 (Parts of Speech) |
- 명사, 동사, 형용사, 부사, 접속사 등 문법적인 표시로 주석 첨부 - 문장의 의미 유추에 도움 |
| Bag-of-Words | - 단어들의 출현 빈도에 집중한 텍스트 데이터의 수치화 표현 방법 (순서 고려하지 않음)<br / >- 단어의 unigram, bigram, n-gram 단계를 고려하여 감정 어휘를 사용해서 주관성 점수 제공 - 일반적으로 감성 분석에서는 bigram, trigram, n-gram이 unigram보다 나은 성능 |
| Feature Hashing (FH) | - 해시 태그가 지정된 단어는 작가가 직접 삽입한 감정과 레이블 »> 매우 유용함 |
기계학습의 방법론
- 전처리
- ML / DL
- Support Vector Machine
- Naive Bayes
- Logistic Regresions
- Random Forest
뉴스 감성분석과 주가 예측
감성분석 대상 데이터
- 주가 데이터
- 시가, 고가, 저가, 종가, 수정종가, 거래량
- 뉴스
- 구글뉴스, 로이터, 야후뉴스
- 2013.02 - 2016.04
수집된 뉴스 텍스트의 긍정, 부정을 판단함
- 주가에 미치는 영향 파악
Feature = 긍정 2,360개 단어, 부정 7,383개 단어
- 기계학습 방법론으로 테스트 (training data)
- Random Forest > 약 88-92%
- Support Vector Machine > 약 86%
- Naive Bayse : 약 83%
- 테스트 데이터로 예측한 결과
- Support Vector Machine > 90%
- Random Forest > 80%
- Naive Bayse > 75%
전체 프로세스
- News collection
- Text preprocessing
- Polarity detection algorithm
- Set polarity score to news
- Document representation
- Classifier learning (model building)
- System evaluation
- Test the model with new data
- Plot time series of past Adj_close price and scoring of news sentiment
- Observe the relationship between news sentiment score and stock price
트위터(StockTweets) 메시지도 정보가 될 수 있다!
- 감성분석 실시
- N-grams와 BN synsets를 조합한 감성분석의 예측력 = 약 72% (가장 높았음)
문장구조 분석과 주가 예측
감성분석 말고 뉴스 헤드라인의 문장 패턴을 구조 분석하면 어떨까?
- 어휘 접근법 > 약 40% 예측
- 어휘 접근법 + 문장 구조 분석 > 82-96% 예측
> 문장 구조를 분석하는 것이 어휘만 분석하는 것보다 더 많은 정보량을 갖고 있다
BERT
구글에서 2018년 개발한 딥러닝 모델, Bidirectional Encoder Representations for Transforms
- 자연어처리 분야에서 가장 우수한 성능
- 트랜스포머(Transformer) 기반 모델
- 사전학습 후 특정 목적을 위해 Fine-Tuning하여 사용
- 양방향 모델이 문장 앞뒤 문맥을 동시에 고려
> BERT 방법론과 거시경제 데이터를 함께 활용해 예측력 우수
- 유가, 금, 환율 등 거시적인 데이터까지 학습 데이터에 포함
- 예측력 향상
자연어처리의 활용
“자연어처리에 관한 많은 논문들이 연구, 발표되고 있고 투자에도 활용되고 있다”
뉴스 등 자연어의 NLP 분석이 주가 예측에 new factor가 될 수 있을까
- 설명력이 있다 = 새로운 (유효) 정보로서 작용하고 있다
- 기존 Pricing Theory에서 사용되지 않았던 새로운 차원의 정보를 다루는 영역
- 최근 빠르게 주목받으며 발전하고 있는 영역
K-mooc, 금융 AI, 중앙대학교 경영학부 유시용 교수님
*자료 출처: 강의자료 (12-2강)