현실 세계의 데이터셋은 다양한 이유로 결측값을 포함하게 된다. 결측값들은 NaN, 공백 또는 기타 기호로 인코딩된다. 결측값이 매우 많은 데이터셋으로 모델을 훈련시키는 것은 학습 모델의 품질에 커다란 영향을 미칠 수 있다. 사이킷런 등 패키지의 학습 알고리즘 일부는 모든 데이터 값이 숫자값이며 모든 데이터가 의미있다고 가정한다.
결측치가 있는 데이터 샘플을 모두 삭제해버리는 것도 방법일 수 있다. 그러나, 가치있는 정보를 포함하는 데이터 포인트들까지 모두 날아갈 수 있다. 조금 더 나은 방법은 결측치를 채우는 것이다. 즉, 우리가 확인할 수 있는 데이터로부터 결측값을 추론해야만 한다. 결측값은 크게 세 가지로 나눌 수 있다:
- Missing completely at random (MCAR)
- Missing at random (MAR)
- Not missing at random (NMAR)
하지만 이 포스팅은 여러 분야에 걸친 데이터셋의 결측치를 채우는 6가지 잘 알려진 방법들을 소개하고자 한다 (시계열 데이터셋은 논외로 한다).
Do Nothing:
첫번째 방법, 아무것도 하지 마라. 알고리즘이 알아서 결측값을 핸들링하게 두면 된다. 일부 알고리즘들은 결측값을 파악하여, 손실함수 값을 기준으로 결측값을 어떻게 채우는 것이 가장 나은 성능을 갖는지 학습한다(ex. XGBoost). 또 어떤 알고리즘들은 그냥 결측값을 무시해 버린다(ex. LightGBM - use_missing=False).
하지만 대부분의 다른 알고리즘들은 패닉에 빠져서 결측값을 어떻게 좀 해보라고 에러를 출력한다(ex. Scikit Learn - Linear Regression). 알고리즘이 에러를 출력했다면, 당신은 결측값을 핸들링해서 클린 데이터셋을 만들어야 한다.
그러면 이제, 모델 학습 전 단계에서 결측값을 채워넣는 다른 방법들을 알아보자.
Note : 이하 모든 예제 데이터셋은 사이킷런의 California Housing Dataset을 사용하였음.
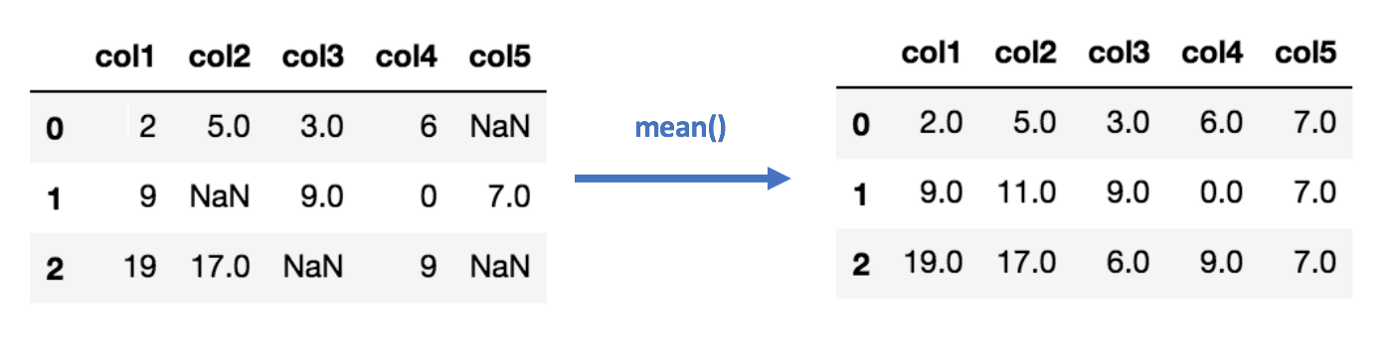
Imputation Using (Mean/Median) Values:
각각의 컬럼 정상값들의 평균/중앙값을 계산한 다음, 해당 컬럼의 결측값을 대체한다. 숫자값을 갖는 데이터 컬럼에만 적용할 수 있다.
Pros:
- 쉽고 빠르다.
- 데이터 샘플이 많지 않은 숫자값 데이터셋에 적합하다.
Cons:
- 변수 간 상관관계를 고려하지 않으며, 컬럼 레벨에서만 적용할 수 있다.
- 인코딩된 카테고리 변수에는 부적합하다(카테고리 변수에는 이 방법을 쓰지 마라).
- 별로 정확하지 않다.
- 결측값 채우는 작업 결과에 대한 불확실성을 설명하지 못한다.
1 | |
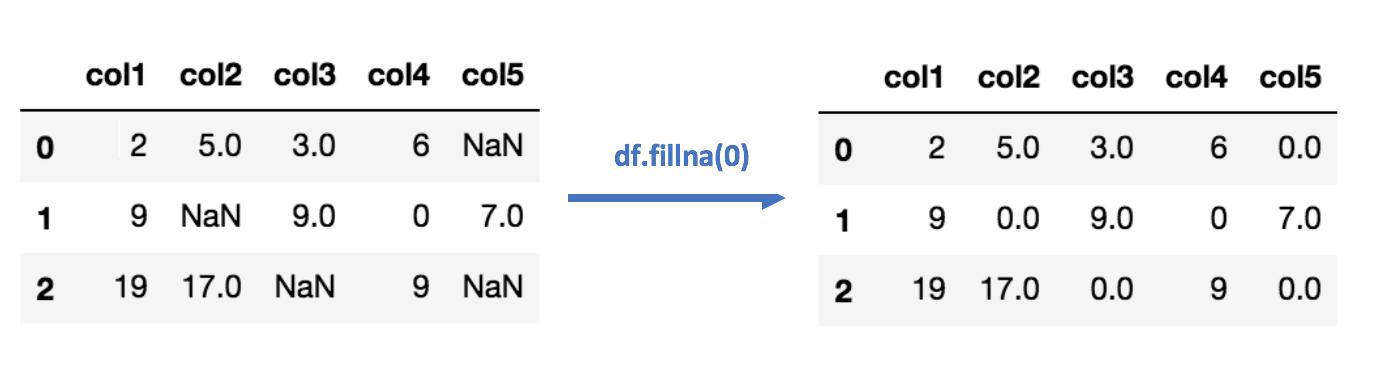
Imputation Using (Most Frequent) or (Zero/Constant) Values:
최빈값은 결측값을 채우는 또 다른 방법이다. 최빈값 대체법은 문자열 또는 숫자로 표현된 카테고리 변수에 대해서도 적용할 수 있다. 그냥 각각의 열에서 가장 자주 등장한 값을 찾아 채워 넣어주면 된다.
Pros:
- 카테고리 변수에 대해서도 적용할 수 있다.
Cons:
- 평균/중앙값과 마찬가지로 변수 간 상관관계를 고려하지 않는다.
- 데이터에 편향성을 만들어낼 수 있다.
1 | |
Zero or Constant 채우기 기법은, 이름 그대로 결측값을 0이나 임의의 상수로 대체하는 것이다.
Imputation Using k-NN:
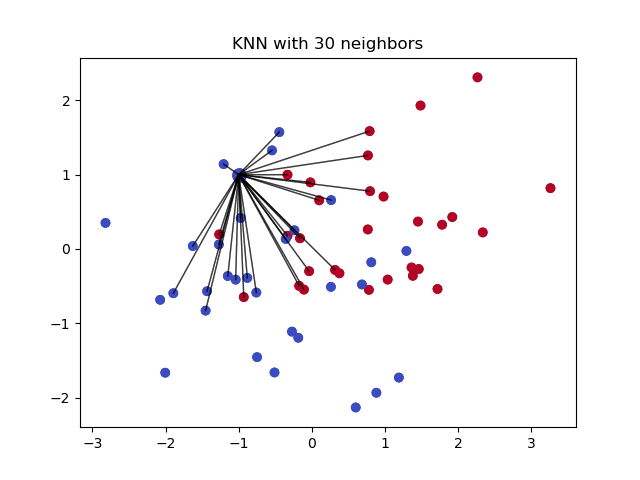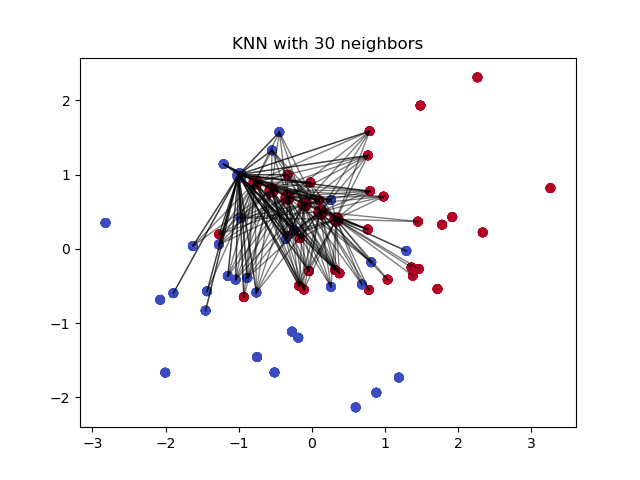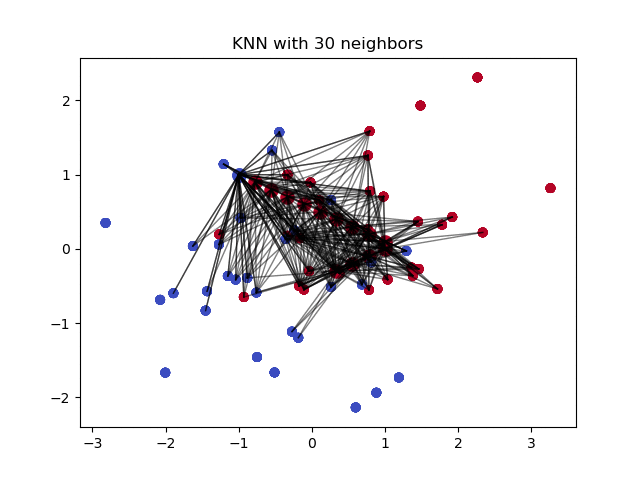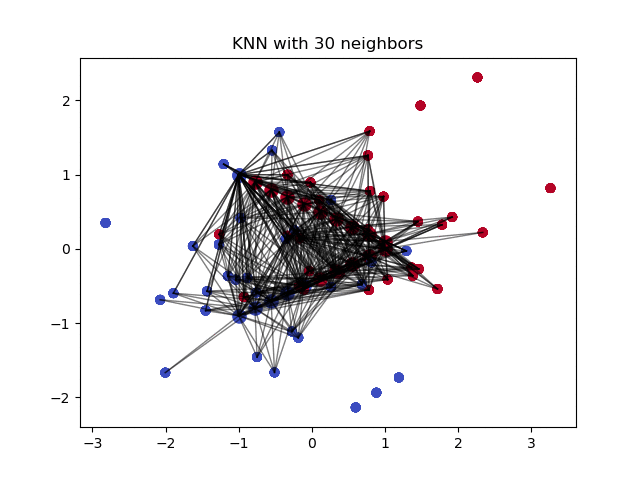
k-nearest neighbours는 단순한 분류에 사용하는 알고리즘이다. 이 알고리즘은 새로운 데이터 포인트의 값을 예측하기 위하여 ‘변수 유사도(feature similarity)’를 사용한다. 새로운 데이터 포인트는 학습 데이터 셋의 포인트 위치와 얼마나 가까운가에 따라 예측값을 할당받게 된다.
이 알고리즘은 결측값이 존재하는 데이터 샘플에 대하여 이웃하는 데이터를 찾아주고, 이웃하는 데이터 샘플들의 정상값들을 바탕으로 결측값을 대체하는 데 유용하게 사용된다. KNN 알고리즘을 결측값 채우기에 사용하는 간단한 Impyute 라이브러리 사용 예제는 다음과 같다:
1 | |
How does it work?
KNN 알고리즘은 기본적인 평균 대체값을 생성하여 만들어지는 완전한 리스트(complete list)를 사용하여 KDTree를 구축한다. 그 다음에 KDTree를 사용해서 가장 가까운 이웃 데이터들(Nearest Neighbours, NN)이 무엇인지 계산한다. k-NN을 찾아내면 알고리즘은 이웃 데이터들의 가중평균을 취한다.
Pros:
- 평균, 중앙값 또는 최빈값 대체법보다 훨씬 정확한 결과를 얻을 수 있다 (데이터셋에 따라 편차 존재).
Cons:
- 컴퓨팅 리소스가 많이 든다. KNN은 메모리 상에 트레이닝 셋을 통째로 올려서 계산하는 알고리즘이다.
- K-NN은 SVM과 달리 데이터에 존재하는 아웃라이어에 꽤 민감(취약)하다.
Imputation Using Multivariate Imputation by Chained Equation (MICE):
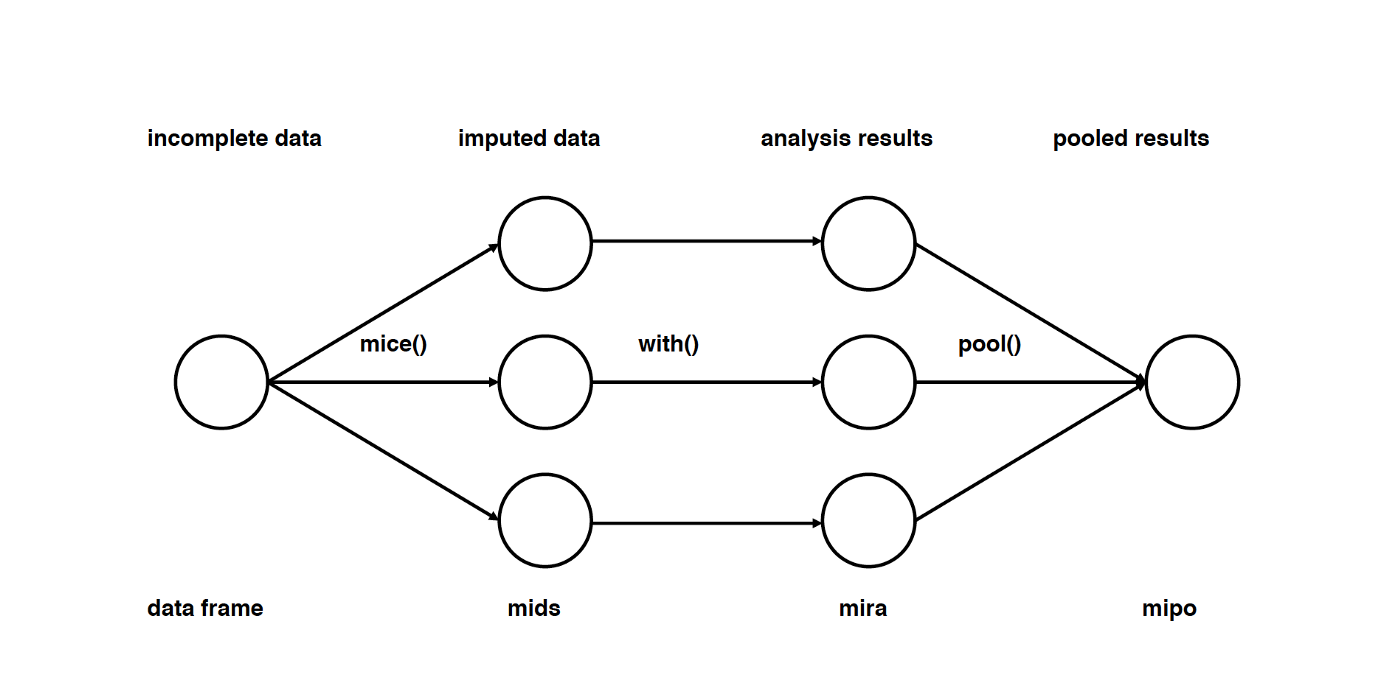
이러한 종류의 결측값 대체법은 결측값을 여러 번 반복하여 채우는 방식으로 수행한다. 다중대체법(Multiple Imputations, MIs)은 더 나은 방식으로 결측값의 불확실성을 측정하기 때문에 대체를 1회 수행하는 것보다 훨씬 좋다.
체인방정식(chained equations) 접근법은 매우 유연해서, 연속적인 실수나 바이너리 등 다양한 변수 자료형을 핸들링할 수 있으며 변수 간 상관성이나 설문조사의 의도적인 응답거부 패턴까지 대응할 수 있다. MICE 알고리즘 작동원리를 더 자세히 살펴보고 싶다면, 관련 연구논문을 살펴보기를 권한다.
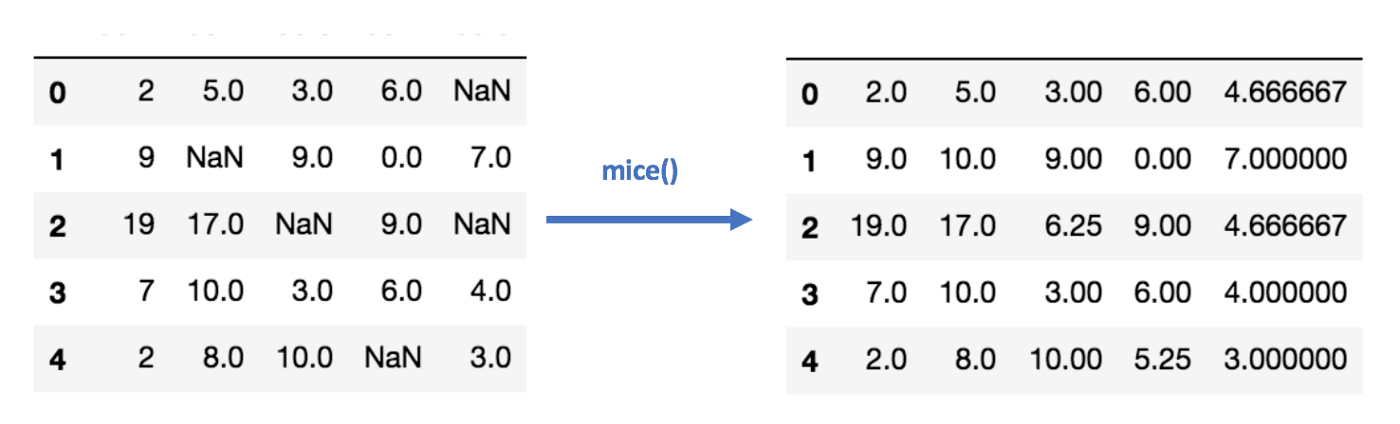
Imputation Using Deep Learning (Datawig):
이 방법은 카테고리 변수와 숫자값이 아닌 변수들에도 잘 작동한다. Datawig는 심층 신경망(DNN)을 사용해서 데이터프레임에 존재하는 결측값을 채우도록 머신러닝 모델을 훈련시키는 라이브러리다. 머신러닝 학습에 CPU와 GPU 모두를 지원한다.
1 | |
Pros:
- 다른 결측값 대체법에 비하여 상당히 정확하다.
- Feature Encoder 등 카테고리 변수를 핸들링할 수 있는 함수들을 제공한다.
- CPU, GPU를 지원한다.
Cons:
- 단일 컬럼에 대해서 적용 가능(Single Column Imputation)하다.
- 데이터 사이즈가 클 경우 상당히 오래 걸릴 수 있다.
- 결측값을 채워넣을 타깃 칼럼과 상관성(ex. correlation)이 높거나, 타깃 칼럼의 정보를 포함하고 있는 다른 칼럼들을 직접 지정해주어야 한다.
Other Imputation Methods:
Stochastic Regression Imputation:
같은 데이터셋에 있는 유관 변수들에 랜덤 잔차값을 더한 값으로부터 회귀 결과를 계산해 결측값을 예측하고자 하는 방법으로, regression imputation과 유사한 방법이다.
Extrapolation and Interpolation:
데이터포인트 집합이 형성하는 일정한 범위에 속하는 다른 데이터 샘플들로부터 결측값을 추정한다.
Hot-Deck Imputation:
상관성이 존재하거나 유사성이 존재하는 변수 집합으로부터 랜덤하게 데이터를 뽑아 결측값을 대체하는 방법이다.
결론적으로, 데이터셋에 존재하는 결측값을 대체하는 완벽한 방법은 없다. 각각의 전략은 특정한 데이터셋과 특정한 결측값 자료형에서 기대 이상으로 작동할 수 있지만, 반대로 형편없이 작동할 수도 있다. 어떤 결측값 자료형에 어떤 전략을 택해야 하는가에 대해서는 일종의 경험칙이 존재하지만, 그보다 당신이 직접 실험하고 어떤 모델이 어떤 데이터셋에 잘 작동하는지 직접 확인하는 것이 좋다.
References:
- [1] Buuren, S. V., & Groothuis-Oudshoorn, K. (2011). Mice: Multivariate Imputation by Chained Equations in R. Journal of Statistical Software
- https://impyute.readthedocs.io/en/master/index.html
(부록) Imputation Algorithm Packages
source : Python imputation algorithm package 정리 by 분석뉴비
- autoimpute
- 카테고리 변수 가능 / 변수 각각에 대하여 개별 처리 가능
- scikit-learn과 호환 가능
- impyute
- mice, em, knn 등 일반적인 결측치 대체법을 제공
- 카테고리 변수는 지원하지 않음
- Scikit-learn 내장 Imputers
- https://scikit-learn.org/stable/modules/impute.html
- Datawig
- 딥러닝을 사용하여 카테고리 변수와 숫자값 아닌 변수에도 잘 작동
- 변수 하나에 대해서만 가능하며 느림
- missingpy
- K-NN 및 랜덤포레스트 기반 결측치 대치법
- 숫자값 변수 및 정수형으로 인코딩한 카테고리 변수 대치 가능
- renom
- 엄밀히 Imputation을 위한 패키지는 아니지만 관련 기능을 제공함
- MIDA (multiple imputation using Denoising Autoencoders)
- 패키지는 아니지만 denoising autoencoder를 이용한 다중대체법(Multiple Imputations) 적용 가능
- https://arxiv.org/abs/1705.02737
- 카테고리 변수에 대해서도 작동 (https://github.com/Oracen/MIDAS/blob/master/midas/midas_base.py)
- knn_impute
- 숫자값 및 카테고리 변수를 모두 지원
- distance-based imputation
위 주제와 관련된 유익한 글들, 참조한 글들, etc.
- 데이터 분석 최대의 적! 결측치(NA값) 처리하기 by 군밤고굼
- 결측치 처리 (Missing Value) by 초코 김현우
- R강의 7. 누락된 자료의 처리 by Keon-Woong Moon
Source
6 Different Ways to Compensate for Missing Values In a Dataset (Data Imputation with examples)
- Will Badr, Jan 5, 2019.