구글은 최근 자사의 인공지능 연구원 Timnit Gebru를 해고했습니다. Gebru의 해고와 함께, 구글이 내놓은 최신 연구 논문은 세계 최대의 AI 연구부서의 무엇을 이야기하고 있을까요?
Is Google’s AI research about to implode?
구글의 인공지능 연구가 정점을 찍은 것은 아마 2017년 10월 19일이었을 겁니다. 이 날은 딥마인드의 데이비드 실버와 동료들이 Nature지에 연구 논문을 발표한 날이었습니다. 알파고 제로라는 이름의 딥러닝 알고리즘이 세계 최고의 바둑기사 뿐 아니라 다른 모든 바둑 프로그램보다 우월하다는 내용의 논문이었죠.
알파고 제로에 대해 가장 눈에 띄는 점은, 사람의 개입이나 도움 없이 작동했다는 점이었습니다. 연구자들이 신경망 네트워크를 설정하고 구동시키면, 신경망 네트워크는 자기 자신과 끝없이 대전을 반복함으로써 수 일 내에 세계 최고의 바둑기사가 되었죠. 체스의 경우에는 세계 최고에 도달하기 위해 몇 시간도 걸리지 않았습니다.
이전까지의 게임 알고리즘과 다르게, 알파고 제로는 알고리즘 내부에 규칙이 삽입되거나 특별한 검색 알고리즘이 들어가 있지 않았죠. 그냥 초보자 수준에서 지구상에서 가장 우월한 레벨이 되기까지 그저 게임을 반복할 뿐인 알고리즘이었죠.
하지만 문제가 있었습니다.
아마도 데이비드 실버와 동료들의 문제는 아니었겠지만, 어쨌거나 문제임은 확실했습니다. 딥마인드의 알파고 제로는 심층 신경망 네트워크가 무엇을 할 수 있는지 보여주었지만, 또한 무엇을 할 수 없는지도 보여주었습니다.
예를 들어, 알파고 제로는 Space Invaders나 Breakout 같은 아타리 게임을 잘 하도록 시스템을 학습시킬 수 있지만, ‘‘일련의 연속된 행동들’‘을 해야만 보상을 얻을 수 있는 Montezuma Revenge같은 게임은 학습할 수 없습니다. 여기서 ‘일련의 연속된 행동들’의 예시는 아래와 같습니다:
- 첫번째 사다리 타고 내려가기
- 로프를 타고 내려가기
- 두번째 사다리 타고 내려가기
- 해골을 뛰어넘기
- 세번째 사다리 타고 오르기
- 열쇠(=보상) 획득하기
알파고 제로는 이러한 종류의 게임들을 잘 학습할 수 없습니다. 왜냐하면 이런 게임들은 사다리, 밧줄 그리고 열쇠의 개념을 이해해야만 하기 때문인데요. 이러한 개념들은 우리 인간들이 세상을 인지하는 모델 속에 구축된 어떤 것들입니다. 또한, 딥마인드가 적용한 강화학습 접근법으로는 습득될 수 없는 어떤 것들이기도 합니다.

Screenshot from Montezuma Revenge
딥러닝 기반 접근법의 한계는 언어 모델에서도 찾아볼 수 있습니다. 구글 브레인, Open AI를 비롯해 여러 연구기관들은 기계에게 언어를 학습시키기 위해 어떤 방법을 사용했는데요. 커다란 문자열 코퍼스들로부터 단어들의 시퀀스와 문장들을 예측하도록 모델을 훈련시키는 접근법이었습니다.
이러한 접근법은 1913년 Andrej Markov가 푸쉬킨의 소설에서 모음과 자음의 순서를 예측한 것과 비슷합니다. 언어 자체에 잘 정의된 패턴이 존재했고, 이러한 패턴을 ‘학습’하면 그 언어를 알고리즘이 사용할 수 있는 것이죠.
언어에서 패턴을 탐지하는 접근법은 언뜻 보기에 그럴듯해 보이는 텍스트를 만들어낼 수 있었습니다. 그럴듯한 텍스트의 좋은 예시로는 GPT-3가 ‘컴퓨터와 세계 평화’를 주제로 작성한 기고문이 있는데, 이 글은 2020년 9월 가디언 지에 게재되어 화제가 되었습니다.
그러나 Emily Bender, Timnit Gebru와 그 동료들이 최근 발표한 논문 ‘On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?‘에서 지적했듯, 이러한 기법들은 우리가 작성하는 글들을 이해하지 못합니다. 그냥 단순히 언어 문자열을 편리한 형태로 저장한 것에 불과하고, 만들어내는 글들은 앵무새처럼 저장된 데이터를 따라하는 수준인 것이죠.
또한, 아래 예시들이 보여주고 있듯이, 이러한 산출물들은 위험하게도 사실과는 거리가 멀 수 있습니다. 음모론 집단 QAnon에 대한 데이터가 워낙 많이 수집된 탓에, GPT-3 모델은 QAnon의 음모론을 그대로 따라한 글을 만들어내게 되었습니다.

Examples of lies and conspiracy theory parotted by GPT-3 (work by Kris McGuffie and Alex Newhouse)
Bender와 그녀의 동료들은, Reddit과 연예 뉴스 사이트 등 연구자들이 이용할 수 있는 많은 텍스트 코퍼스가 부정확한 정보를 담고 있으며, 따라서 세상을 매우 편향된 관점으로 표상하고 있다고 설명합니다. 특히, 20대 백인 남성들은 이러한 부정확한 사실을 담은 코퍼스에 무방비하게 노출되고 있습니다. 게다가, 커다란 데이터셋에 대해서 특정 부분을 “수정”하는 작업은, 예를 들어 성별에 대한 참조나 추정을 삭제하고자 할 때, LGBT 등 성소수자들의 목소리가 과소평가될 위험이 있습니다.
불투명하고 무책임한 데이터로 인하여, 언어 모델들은 가디언 기고문 재롱잔치만큼이나 무의미해질 수 있습니다(이는 필자의 의견이며, Bender 등 논문 저자의 의견이 아님). 더욱이, 무의미함을 넘어서 커다란 부정적 영향을 만들어내게 되는데, 부정확한 사실로 가득한 텍스트를 만들어내기 위해 환경에 악영향을 끼칠 만큼의 컴퓨팅 자원들을 소모한다는 것입니다.
Gebru, Bender 등이 작성한 위 논문은 구글 내부 검토에서 출판을 거부당했습니다. 하지만 외부기관의 엄격한 리뷰를 거친 뒤에서야 받아들여졌죠. Gebru는 연구논문에서 이름을 빼 달라는 상급자의 요청을 반대했다가 해고당했습니다. 그럼에도 구글에서 머신러닝 연구가 이루어지는 방식을 비판하는 건 Gebru 뿐만은 아닙니다.
Gebru가 해고당하기 몇 주 전 나온 기사에 따르면, 다양한 부서에서 근무하는 40명의 구글 연구원들은 범용 머신러닝 접근법에 대해서 강도높게 이의를 제기했습니다. 이들은 그들의 주장을 뒷받침하기 위해, 감염병 유행을 모델링하는 것을 예시로 들었는데요.
아래 이미지는 하나의 머신러닝 모델이 서로 다른 두 개의 가정을 기반으로 예측한 두 개의 감염병 유행 커브를 보여주고 있습니다. 알고리즘에 따르면 두 개의 커브는 동일하게 좋은 것으로 평가되지만, 감염병 유행 규모에 대해 매우 다른 예측을 내놓고 있습니다.
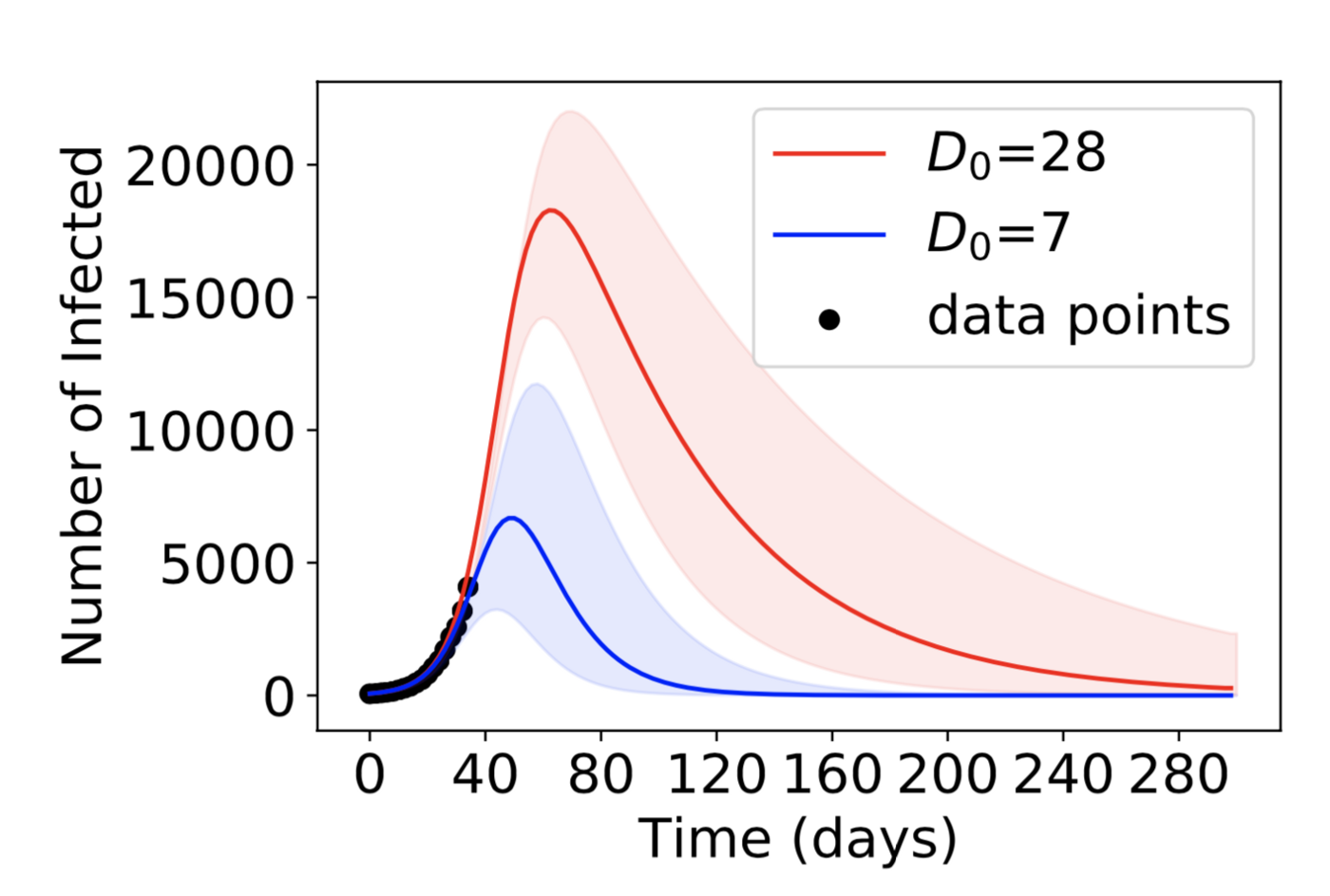
How two different epidemic models (blue and red) with very different assumptions can both fit the existing data but give very different predictions
이것은 비명세성 문제(underspecification problem)으로 알려진 것의 사례이기도 합니다. 40명의 연구원들이 주장했듯, 비명세성은 모던 머신러닝의 신뢰성에 매우 중대한 의문을 제기하고 있습니다. 비명세성 문제는 종양 탐지, 자율주행 그리고 언어 모델에 걸친 머신러닝 전 분야에 해당될 수 있기 때문입니다.
참고 글:
- [MIT Tech Review] 우리가 인공지능을 훈련시키는 방식에는 근본적 결함이 있다
- [아주경제] 같은 데이터 학습해도 AI 모델마다 성능 달라… 구글, AI의 비명세성 문제 제기
응용수학자로 25년 동안 일해 온 입장에서, 40명의 연구원들이 제기한 주장은 낯설지 않습니다. 응용수학자들은 비명세성 문제를 수십년 전부터 인지하고 있었습니다. 때때로, 특정 데이터셋을 잘 설명하는 모델이 수없이 나오기도 합니다. 어느 모델이 최선의 모델인지 어떻게 식별할 수 있을까요? 정답은 “할 수 없다” 입니다. 또는 적어도 추가적인 가정들을 정립하지 않는 한 불가능합니다.
만약 우리가 감염병 확산을 모델링하고자 한다면, 우리는 사람들의 행동에 대한 가정을 수립해야 합니다. 사람들은 봉쇄 조치에 어떻게 대응할 것인가, 사람들은 백신에 대해 어떻게 대응할 것인가 등에 대해서죠. 우리는 우리가 가정할 수 있는 모든 것을 측정할 수는 없음을 알고 있습니다. 따라서 우리가 만들 가정들이란 우리가 알지 못하는 것들 중에서 어떠하리라고 추정되는 것들 을 문서화한 결과가 될 겁니다.
일반적으로, 수학적 모델링은 세 가지로 구성됩니다:
- 가정 : 인간의 경험과 직관으로부터 비롯하며, 문제에 대한 사고를 전개하기 위한 기초가 됨
- 모델 : 우리가 추론할 수 있는 방식으로 우리의 가정을 어떤 형태나 방법으로 표현한 것 (i.e. 방정식 또는 시뮬레이션)
- 데이터 : 현실 세계에 대하여 우리가 측정하고 이해한 것
구글의 머신러닝 연구 프로그램이 지난 5년 간 강세를 보였던 분야는 수학 모델링의 두 번째 요소, 모델 분야에 대해서였습니다. 특히, 구글은 사진과 단어에 대한 신경망 네트워크 모델이라는 하나의 특정한 모델을 끊임없이 발전시켜 왔습니다. 하지만 그 모델 또한 거의 무한에 가까운 대체 모델들 중 하나에 불과합니다. 세상을 바라보는 한 가지의 방법이라는 의미입니다.
순수한 머신러닝 접근법을 추구하는 모델 연구자들은 아주 강하고 절대적인 가정을 세웁니다: 그들의 모델은 가정을 필요로 하지 않는다는 가정이죠. 응용수학자들이 오랫동안 인지해 온, 그리고 구글 연구원 40명이 이제서야 주장하는 비명세성 문제는 바로 이러한 접근이 옳지 않음을 보여주고 있습니다. 모든 모델은 가정을 필요로 합니다.
‘모델은 가정으로부터 자유롭다’는 가정은 확률적 앵무새 따라하기 문제로 이어집니다. 신경망 네트워크 접근법과 관련해 딥마인드가 내세우는 장점은, 모델이 데이터로부터 직접 학습한다는 것입니다. 결과적으로, 신경망 네트워크 모델이 궁극적으로 학습하는 것은 데이터가 담고 있는 내용 그 이상도 이하도 아니게 됩니다. 체스, 바둑 또는 breakout과 같은 컴퓨터 게임들에 있어 이것은 문제가 아닙니다. 연구자들은 게임을 시뮬레이팅함으로써 무한한 데이터를 모델에 공급해 승리하도록 만들 수 있습니다.
그러나, 단어나 이미지로부터 학습하는 문제에서 데이터는 두 가지 이유로 극심하게 제한됩니다. 첫째로, 인간의 대화는 게임보다 훨씬 더 복잡합니다. 인간의 대화는 Montezuma Revenge에서의 열쇠나 해골 등과 같은 사물의 의미를 비언어적 방식으로 이해하는 것을 포함하기 때문입니다. 둘째, 우리는 매우 한정된 데이터셋에 대해서만 접근합니다. 레딧과 가십 뉴스 사이트에 수십억 개의 단어가 있다 하더라도, 이는 우리가 사용하는 언어를 매우 좁은 범위에서 표상하고 있을 뿐입니다.
이런 방법으로 인간의 진짜 언어를 학습할 수는 없다는 사실을 이해하기 위해 비트겐슈타인이 될 필요는 없을 겁니다. 신경망 네트워크는 엄청나게 거대한 단어들의 데이터베이스를 매우 압축적으로 표상하는 것에 지나지 않습니다. 따라서 GPT-3 또는 BERT가 뭔가를 “이야기”한다면, 그것이 해주는 이야기는 어떤 특정 그룹에 속한 문장들과 문장구조들이 텍스트에서 함께 등장할 확률이 높다는 것 정도입니다.
그리고 모델에 의해서 어떠한 가정도 수립되지 않았으므로, Bender와 동료들이 지적한 바와 같이, 신경망 네트워크는 Reddit의 콘텐츠를 확률적으로 따라하는 것밖에 학습할 수 없습니다.
특히 Timnit Gebru, Margaret Mitchell(다른 구글 연구원), 그리고 MIT의 Joy Buolamwini는 기술적 도전과제에 대한 중요한 인사이트를 내놓았습니다. 이들은 기술적 난제의 해결이 다음 두 가지에 달려 있다고 이야기합니다.
- 언어와 이미지 데이터셋을 가능한 ‘중립(neutral)’ 상태로 조직하고 구축할 방법을 찾는 것 (Gebru의 얼굴인식 작업, 아래 그림)
- 연구원 스스로 언어와 이미지 데이터의 완벽한 중립성은 불가능하다는 것을 인정하는 것

Example images from the Pilot Parliaments Benchmark (PPB) dataset, taken from Buolamwini and Gebru (2018). The aim of creating data sets like this — which are more balanced by gender and skin type — is to aid both with the training and testing of face recognition models.
만약 우리가 가진 텍스트와 이미지 라이브러리가 성차별주의자와 인종차별주의자에 의해 만들어진다면, 우리는 그 데이터에서 중립성을 기대할 수 있을까요? 기대할 수 없습니다. 만약 우리가 어떠한 가정도 없이 Reddit으로부터 모델을 학습시킨다면, 우리의 가정은 Reddit이 정하는 것이 됩니다. Bender, Gebru, Mitchell과 Buolamwini가 보여주었듯, 만약 우리가 이러한 접근법을 계속 유지해 나갈 것이라면, 투명하고 책임감 있는 방식으로 데이터와 모델을 만들어낼 방법을 찾는 데 집중해야 할 겁니다.
구글 인공지능 연구부서인 구글 브레인에 희망은 있을까요? 제가 이 글에서 인용한 대부분의 구글 비판들은 바로 구글에서 근무하는 연구원들에게서 나왔습니다. 그러나, 모던 AI 전체를 통틀어 구글 브레인이 내놓은 연구 중에서도 세 손가락에 꼽힐 만한 논문의 저자인 Gebru를 구글이 해고했다는 사실은 심히 우려스럽습니다.
만약 ‘구글러’ 다수를 대표한다는 구글 리더들이 아주 부드러운 수준의 내부 비판마저 수용하지 못한다면, 기업 혁신은 물건너간 이야기입니다. 이러한 실책으로 말미암아, ‘가정으로부터 자유로운’ 신경망 네트워크를 주장하는 이들이 구글 내부에서 한층 늘어날 위험이 있습니다.
모든 위대한 연구는 흥망성쇠를 거칩니다. 하나의 모델 가정이 또 다른 모델 가정을 뒤엎으면서 떠오르듯이 말이죠. 이 글의 서두에서 밝혔듯, 딥마인드의 접근법은 인상적인 결과를 만들어 냈습니다. 그렇지만, 그 연구의 초석이 된 아이디어 대부분은 구글 내부로부터 나온 아이디어가 아닙니다. Geoffrey Hinton과 그 동료들이 수십년 전부터 지속해온 연구들로부터 시작되어, 주로 대학교 연구소 시스템 내부에서 도출된 것들이죠. Hinton의 접근법의 진정한 잠재력을 알아차리기까지 수십 년이 걸렸습니다. 구글은 연구원들의 꿈을 실현할 수 있는 시간과 컴퓨팅 리소스를 제공해서 라스트 스퍼트를 이끌어냈을 뿐이죠.
제가 걱정하는 것은, 구글에서 근무하는 연구원들이 새로운 아이디어를 제시했을 때 구글이 위협으로 받아들이지는 않을까 하는 것입니다. 구글이 사내의 가장 혁신적인 연구원을 해고해서 진정 새로운 연구를 진행하고자 하는 연구집단을 셧다운시킨 것은 분명 크나큰 위협입니다.
저는 Gebru의 해고 이면에 존재하는, 조직 깊숙이 침투한 성차별주의와 인종차별주의 문제를 평가절하하고 싶지 않습니다. 성차별과 인종차별 외에도 구글이 진심으로 한심한 일을 저질렀다는 것이 제가 하고자 하는 이야기입니다. 구글은 자사가 보유한 최고의 브레인에게 최상의 자원을 제공하는 대신, 문을 굳게 걸어잠그고 과거의 영광만을 쳐다보고 있습니다.
의문형 헤드라인이 마침표로 끝나는 것은 으레 있는 일이 아니지만, 이 경우에는 마침표로 끝나는 것이 자연스러워 보입니다: 구글 브레인의 연구는 내부적으로 붕괴하고 있는가.
아마도 언젠가 우리는 신경망 네트워크의 복잡한 데이터를 표상하는 방법론에 있어서 전환이 일어나는 것을 볼 지도 모릅니다. 기존의 Hinton 방법론으로부터, 투명성과 책임성을 갖추고자 하는 Gebru 방법으로 말이죠. 이것은 마치 뉴턴에서 아인슈타인으로의 전환과도 유사할지도 모릅니다. 그리고 만약 그렇게 된다면, 구글은 AI의 진보를 주도했다고 말할 수 없을 겁니다.
출처
Is Google’s AI research about to implode? by David Sumpter, Feb 20 2021